The Versatile ELT BlogA space for short articles about topics of interest to language teachers.
Subscribe to get notified of
|
 One swallow does not summer make
Hoey in fact studied foreign languages so that he could experience the processes of language learning and the practical applications of linguistic and pedagogical theory. When he was observing language in context, that is by reading and listening, he would notice certain collocations but he needed proof of their typicality before he could consider them worth learning. Just because someone has combined a pair of words does not mean that this combination is a typical formulation in the language. The lexicographer, Patrick Hanks (1940–2024) felt the same: Authenticity alone is not enough. Evidence of conventionality is also needed (2013:5). Some years before these two Englishman made these pronouncements, Aristotle (384–322 BC) observed that one swallow does not a summer make. Other languages have their own version of this proverb, sometimes using quite different metaphors, but all making the same point. In order to ascertain that an observed collocation is natural, typical, characteristic or conventional, it is necessary to hunt it down, and there is no better hunting ground for linguistic features than databases containing large samples of the language, a.k.a corpora. In the second paragraph, Hoey experienced the processes … Is experience a process a typical collocation? This is the data that CorpusMate yields:  In the same paragraph, we have the following collocation candidates:
Here is some more data from CorpusMate.  In the following example, we have a wildcard which allows for one element to appear between the two words of the collocation. Even in these first 12 of the 59 results, other patterns are evident.  The process of validating your findings through multiple sources or methods is known as triangulation, and it is an essential stage in most research. When we train students to triangulate their linguistic observations, it is quite likely that they are familiar with this process from their other school subjects. This is not just a quantitative observation, i.e. this collocation occurs X times in the corpus. It is qualitative as well: the students observe other elements of the cotext, such as the use of other words and grammar structures that the collocation occurs in. They might also observe contextual features that relate to the genres and registers in which the target structure occurs. They are being trained in task-based linguistics as citizen scientists, engaging their higher order thinking skills as pattern hunters. This metacognitive training is a skill for life that will extend far beyond the life of any language course they are undertaking. Triangulation does not apply only to collocation. Any aspect of language can be explored in this way. You may have noticed the word order in the idiom: does not a summer make. Many people have run with this curious word order and exploited it creatively. It is thus a snowclone. Here are some examples from SkELL.  Respect our students' intelligence and equip them to learn language from language. ReferencesCroswaithe, P. & Baisa, V. (2024) A user-friendly corpus tool for disciplinary data-driven learning: Introducing CorpusMate International Journal of Corpus Linguistics.
Hanks, P. (2013) Lexical Analysis: Norms and Exploitations. MIT. Hoey, M. (2000) A world beyond collocation: new perspectives on vocabulary teaching. Teaching Collocation. Further Developments in the Lexical Approach. LTP (ed. Lewis, M.)
0 Comments
 The mighty power of the asteriskFollowing on from my previous post about constellations, in this post I'm looking at the asterisk, which some of my students refer to as a star. I admit that that's a pretty tenuous connection and I apologise whole-heartedly. But the universe does get a mention here, so bear with me. I'm drafting a vocabulary workbook at the moment, or should I say yet another vocabulary workbook. In this one, the students are often tasked with discovering how words work in grammar patterns. They mainly use CorpusMate. This is quite a new, free, open-access and superfast corpus tool that was designed by Peter Croswaithe and programmed by Vit Baisa, who also programmed my VersaText and was instrumental in the development of SkELL. The CorpusMate corpus does not have part of speech tagging, which means that you can't search for a pattern such as Verb + noun + v-ing and there are hundreds of verbs in English that function in this pattern, e.g. remember, picture, catch, tolerate, leave. There are not only hundreds of words, but there are also hundreds of patterns that nouns, verbs and adjectives function in. My current vocabulary book revolves around the COBUILD grammar pattern reference books from the late 1990s. In fact, I wrote my masters dissertation on the grammar patterns of the verbs in the then new Academic Wordlist (2000) that Averil Coxhead had created for her masters dissertation. It is always interesting to see how much can be gleaned about the grammar pattern of a word without part of speech tags. The asterisk is mighty. In fact, it holds the secret to the meaning of life, the universe and everything. Read on! A supercomputer called Deep Thought was asked what the meaning of life, the universe and everything was. It calculated that it was 42. See the announcement in this extract from the film. Douglas Adams, the author of The Hitchhiker's Guide to the Galaxy, the cult 1979 novel from which this comes, always claimed that he chose the number 42 randomly. But 42 is the ASCII code for the asterisk, which in computer searches means anything and everything. Did Deep Thought calculate that the meaning of life, the universe and everything is anything and everything? This search uses two asterisks. The first has spaces before and after it, which makes the program search the corpus for all of the words in between the items to the left and the right of it. The second asterisk is used with a dot and is attached to ing. Dot-star, as my students call it. This makes the program search for words ending with ing. While this might include words such as thing and during, the fact is that the -ing word that follows remember followed by another word tends to be an -ing verb. This is the reality of pattern grammar.  Click this link to see the first 250 of the 589 results of this search. This data is automatically sorted so that this pattern in the use of remember can be gleaned. To make these patterns even more visible and student friendly, clicking on the Pattern finder button generates a tidy table. Here are the top nine entries in that table. 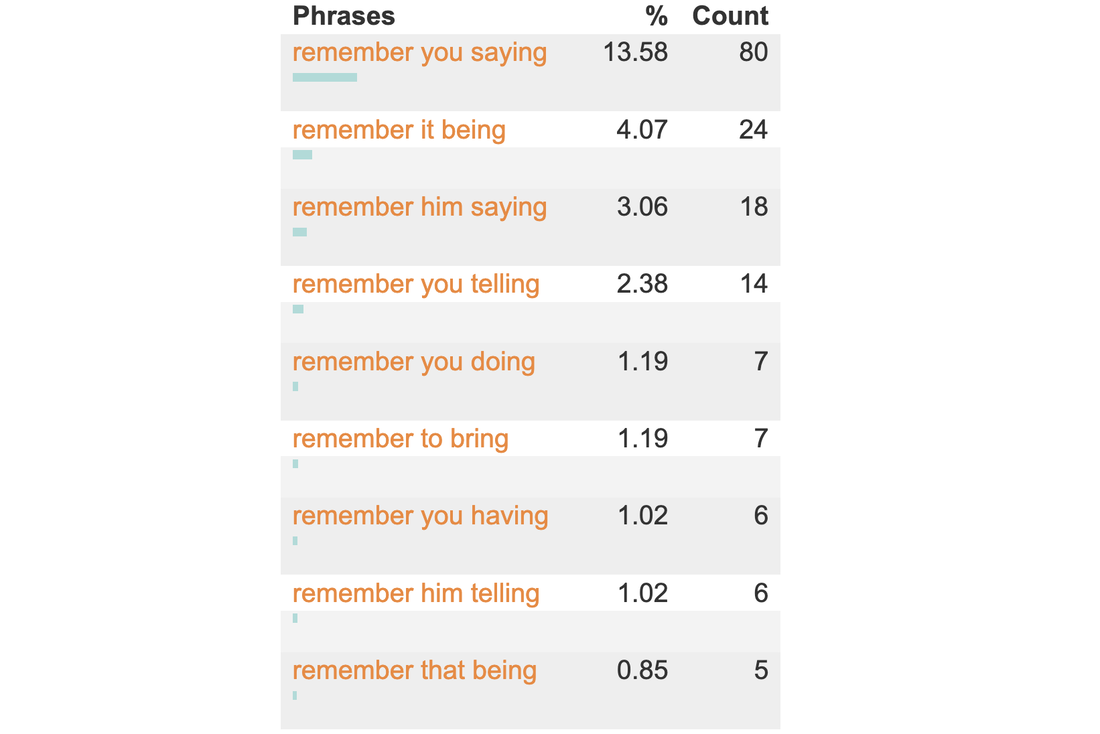 As mentioned, Verb + noun + -ing is one of hundreds of grammar patterns of words that the COBUILD team uncovered. They were not the first to identify this or many other patterns, but they were able to demonstrate with large corpora the semantic relationships between words that function in the same pattern. This means that the words in a grammar pattern are related in meaning. Important and interesting. Chunks Now back to our mighty asterisk! With queries such as these, you can find the frequent chunks that a target word is used in. The concordance extract below shows some things that people are "in search of a".   I'm hoping that a vocabulary workbook that has students learning about the patterns that words function in and the words that go in these patterns through tasking them with discovering these properties of words for themselves using CorpusMate and other tools will be a stimulating voyage of discovery which will add a layer of systematicity to their vocabulary study which will in turn lead to them using words with more confidence and fewer hesitations. Think fluency. They might become stars themselves!
|

Services |
Organisation |
© COPYRIGHT 2018. ALL RIGHTS RESERVED. |